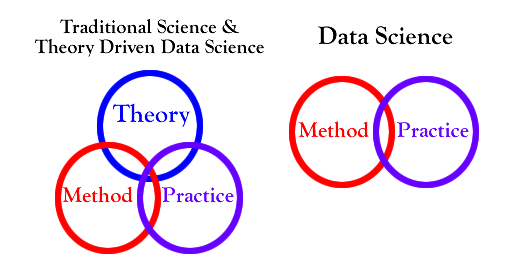
I’ve been trying to build a base literature for “data pattern analysis.” Data pattern analysis helps build better data science models by providing clues about latent processes that we cannot observe. A theoretical model of these latent processes can be used to develop a “theory driven data science.”
In general, as shown in the graphic above, the practice of data science is largely devoid of theoretical input. This was pointed out by Chris Anderson’s post titled “The End of Theory: The Data Deluge Makes the Scientific Method Obsolete”. He argued that there is so much data available that all one needs is a good data extraction model to get value from the data.
There is some merit to his observations. The approaches used in data science do provide inference without theory and provide better predictive models that traditional science. However, the basic premise that theory is not needed is flawed.
The problem with lack of theory is the “missing data problem” (52 Weeks of Data Pattern Analysis: Week 5: The Healthcare Dilemma). In many important areas where data science is used, we are observing latent processes where over 90% of the data is missing. Theory has the power to enhance data science by providing a model of this missing data. I suggest that throwing out theory in the shift to data science is like “throwing the baby out with the bath water.”
First, theory can dramatically improve the predictive power of data science models. In my own experience, a more accurate theory regarding the nature of health helped increase the explained variance in a population health ranking model by 50%.
Second, theory provides an enhanced ability to create prescriptive models in addition to predictive models. Data science without theory is unlikely to provide prescriptive solutions. If we actually want to fix something, having an accurate theoretical understanding of how it works will make it more likely that we will succeed.
The Nature of Theory Driven Data Science
If we examine the problems related to traditional scientific theories, one issue becomes clear. Traditional scientific theories tend to be “micro theories.” One causal factor, or at most a few factors, are proposed to “cause” something.
For example, in criminology, “low self-control” is proposed as a “cause” of crime. There is a correlation between low self-control and the commission of criminal acts. Therefore, “control theory” is a popular scientific theory of criminal behavior.
The problem is that crimes are the result of an infinite variety of genetic and environmental factors. A good data science model will out predict a micro theory model every time. Micro-theories are typically too restrictive to be of much use outside of academia.
The type of theory that I propose for “theory driven data science” is a macro-theory. We need to understand the “nature of nature.” How do living systems function? How might that knowledge help us build better data science predictive models? How might this knowledge help us fix problems that arise?
A Physics of Living Systems (The Facts of Life)
I propose that a theory driven data science should provide a macro focus rather than a micro focus. I have narrowed the theoretical issues that are most important for data science with living systems down to three main areas that I call “the facts of life.” Life is 1) variable, 2) dynamic, and 3) selective.
Life is Infinitely Variable
First life is variable and has an infinite variety of possibilities. Life is a function of gene environment interactions (GxE). Tens and hundreds of thousands of genes interact with an infinitely variable environment. If we look at the number of possible interactions it is 2N, where N is the number of possible individual factors (https://en.wikipedia.org/wiki/Interaction_(statistics)). I argue that since the smallest genome found so far has 182 genes and humans have over 3 billion genes (https://en.wikipedia.org/wiki/Genome), for all intents and purposes, life is infinitely variable.
Life is Always Dynamic
Living systems are constantly fluctuating. There are two important dynamics that need to be addressed by data science. First, life is a function of high dimensional chaos. Living systems are constantly shifting their behavior in response to the environment. Second, living systems develop over time. They have a beginning, growth and decline, and an end. The first factor leads to short term fluctuation, and the second leads to long term variation in the behavior of the system. I will argue that a theory driven data science will address the issues related to dynamic variability.
Life is Selective
Living systems operate within normal ranges and we seldom consider their function until the system falls outside the “normal” range of functioning. This poses a big problem in criminology, health care, and may other disciplines. Since we usually don’t observe “normal” behavior, and tend to focus on the abnormal behavior, we are typically missing over 90% of the data. This is an under explored area and needs to be addressed if model accuracy is to be improved.
Conclusion
I propose that a “theory driven data science” provides dramatically better prediction and enhances the possibility for prescriptive data science. By focusing on “the facts of life” one can build better data science models.
The work on a theory driven data science is based on 17 years of data analysis, intense study, and a lot of deep thinking. Most of the physical work is buried in a mass of spreadsheets, statistical models, and written documents on my hard drives.
I have been trying to pull this work out and craft it into some sort of organized set of ideas and proof of concept documents. If you go back over my LinkedIn posts, and blogs on https://www.datapatternanalysis.com you will find some bits and pieces.
The previous work I posted is based on the three facts of life that I proposed above.
Recent Comments